The Imaginary trick |12 March 2021|
tags: math.OC
Most of us will learn at some point in our life that 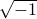 is problematic, as which number multiplied by itself can ever be negative?
To overcome this seemingly useless defiency one learns about complex numbers and specifically, the imaginary number
is problematic, as which number multiplied by itself can ever be negative?
To overcome this seemingly useless defiency one learns about complex numbers and specifically, the imaginary number 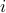 , which is defined to satisfy
, which is defined to satisfy 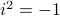 .
At this point you should have asked yourself when on earth is this useful?
.
At this point you should have asked yourself when on earth is this useful?
In this short post I hope to highlight - from a slightly different angle most people grounded in physics would expect - that the complex numbers are remarkably useful.
Complex numbers, and especially the complex exponential, show up in a variety of contexts, from signal processing to statistics and quantum mechanics. With of course most notably, the Fourier transformation.
We will however look at something completely different. It can be argued that in the late 60s James Lyness and Cleve Moler brought to life a very elegant new approach to numerical differentiation. To introduce this idea, recall that even nowadays the most well-known approach in numerical differentiation is to use some sort of finite-difference method, for example, for any  one could use the central-difference method
one could use the central-difference method
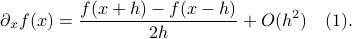
Now one might be tempted to make  extremely small, as then the error must vanish!
However, numerically, for a very small the two function evaluations
extremely small, as then the error must vanish!
However, numerically, for a very small the two function evaluations  and
and  will be indistinguishable.
So although the error scales as
will be indistinguishable.
So although the error scales as 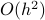 there is some practical lower bound on this error based on the machine precision of your computer.
One potential application of numerical derivatives is in the context of zeroth-order (derivative-free) optimization.
Say you want to adjust van der Poel his Canyon frame such that he goes even faster, you will not have access to explicit gradients, but you can evaluate the performance of a change in design, for example in a simulator. So what you usually can obtain is a set of function evaluations
there is some practical lower bound on this error based on the machine precision of your computer.
One potential application of numerical derivatives is in the context of zeroth-order (derivative-free) optimization.
Say you want to adjust van der Poel his Canyon frame such that he goes even faster, you will not have access to explicit gradients, but you can evaluate the performance of a change in design, for example in a simulator. So what you usually can obtain is a set of function evaluations 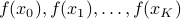 . Given this data, a somewhat obvious approach is to mimick first-order algorithms
. Given this data, a somewhat obvious approach is to mimick first-order algorithms
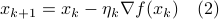
where 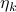 is some stepsize. For example, one could replace
is some stepsize. For example, one could replace 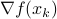 in
in 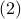 by the central-difference approximation
by the central-difference approximation 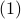 .
Clearly, if the objective function
.
Clearly, if the objective function 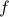 is well-behaved and the approximation of is reasonably good, then something must come out?
As was remarked before, if your approximation - for example due to numerical cancellation errors - will always have a bias it is not immediate how to construct a high-performance zeroth-order optimization algorithm. Only if there was a way to have a numerical approximation without finite differencing?
is well-behaved and the approximation of is reasonably good, then something must come out?
As was remarked before, if your approximation - for example due to numerical cancellation errors - will always have a bias it is not immediate how to construct a high-performance zeroth-order optimization algorithm. Only if there was a way to have a numerical approximation without finite differencing?
Let us assume that 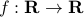 is sufficiently smooth, let be the imaginary number and consider the following series
is sufficiently smooth, let be the imaginary number and consider the following series
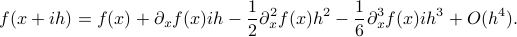
From this expression it follows that
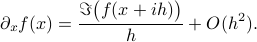
So we see that by passing to the complex domain and projecting the imaginary part back, we obtain a numerical method to construct approximations of derivatives without even the possibility of cancellation errors. This remarkable property makes it a very attractive candidate to be used in zeroth-order optimization algorithms, which is precisely what we investigated in our new pre-print. It turns out that convergence is not only robust, but also very fast!