Risky Business in Stochastic Control: Exponential Utility |12 Jan. 2020|
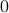 in the end of time. In the noiseless case, no problem. But now say there is a substantial amount of noise, do you still want such a slow control law? The answer is most likely no since you quickly drift away. The classical LQR formulation does not differentiate between noise intensities and hence can be rightfully called naive as Bertsekas did (Bert76). Unfortunately, this name did not stuck.
in the end of time. In the noiseless case, no problem. But now say there is a substantial amount of noise, do you still want such a slow control law? The answer is most likely no since you quickly drift away. The classical LQR formulation does not differentiate between noise intensities and hence can be rightfully called naive as Bertsekas did (Bert76). Unfortunately, this name did not stuck. Can we do better? Yes. Define the cost function
![gamma_{T-1}(theta) = frac{2}{theta T}log mathbf{E}_{xi}left[mathrm{exp}left(frac{theta}{2}sum^{T-1}_{t=0}x_t^{top}Qx_t + u_t^{top}Ru_t right) right]=frac{2}{theta T}log mathbf{E}_{xi}left[mathrm{exp}left(frac{theta}{2}Psi right) right]](eqs/6416747510437753707-130.png)
and consider the problem of finding the minimizing policy 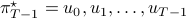 in:
in:
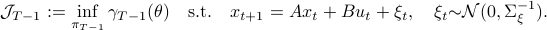
Which is precisely the classical LQR problem, but now with the cost wrapped in an exponential utility function parametrized by 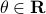 .
This problem was pioneered by most notably Peter Whittle (Wh90).
.
This problem was pioneered by most notably Peter Whittle (Wh90).
Before we consider solving this problem, let us interpret the risk parameter . For 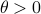 we speak of a risk-sensitive formulation while for
we speak of a risk-sensitive formulation while for 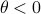 we are risk-seeking. This becomes especially clear when you solve the problem, but a quick way to see this is to consider the approximation of
we are risk-seeking. This becomes especially clear when you solve the problem, but a quick way to see this is to consider the approximation of 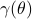 near
near 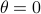 , which yields
, which yields ![gammaapprox mathbf{E}[Psi]+frac{1}{4}{theta}mathbf{E}[Psi]^2](eqs/7712769251826009795-130.png) , so
, so 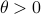 relates to pessimism and to optimism indeed. Here we skipped a few scaling factors, but the idea remains the same, for a derivation, consider cumulant generating functions and have a look at our problem.
relates to pessimism and to optimism indeed. Here we skipped a few scaling factors, but the idea remains the same, for a derivation, consider cumulant generating functions and have a look at our problem.
As with standard LQR, we would like to obtain a stabilizing policy and to that end we will be mostly bothered with solving 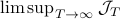 .
However, instead of immediately trying to solve the infinite horizon average cost Bellman equation it is easier to consider
.
However, instead of immediately trying to solve the infinite horizon average cost Bellman equation it is easier to consider 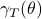 for finite
for finite 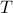 first. Then, when we can prove monotonicty and upper-bound
first. Then, when we can prove monotonicty and upper-bound 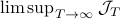 , the infinite horizon optimal policy is given by
, the infinite horizon optimal policy is given by 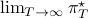 .
The reason being that monotonic sequences which are uniformly bounded converge.
.
The reason being that monotonic sequences which are uniformly bounded converge.
The main technical tool towards finding the optimal policy is the following Lemma similar to one in the Appendix of (Jac73):
Lemma 
Consider a noisy linear dynamical system defined by 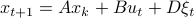 with
with 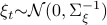 and let
and let 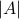 be shorthand notation for
be shorthand notation for 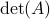 . Then, if
. Then, if 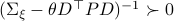 holds we have
holds we have
![mathbf{E}_{xi}left[mathrm{exp}left(frac{theta}{2}x_{k+1}^{top}Px_{k+1} right)|x_kright] = frac{|(Sigma_{xi}-theta D^{top}PD)^{-1}|^{1/2}}{|Sigma_{xi}^{-1}|^{1/2}}mathrm{exp}left(frac{theta}{2}(Ax_k+Bu_k)^{top}widetilde{P}(Ax_k+Bu_k) right)](eqs/8871996922177725349-130.png)
where
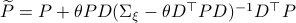 .
. 
Proof
Let ![z:= mathbf{E}_{xi}left[mathrm{exp}left(frac{theta}{2}x_{t+1}^{top}Px_{t+1} right)|x_tright]](eqs/2205886115745182034-130.png) and recall that the shorthand notation for is , then:
and recall that the shorthand notation for is , then:
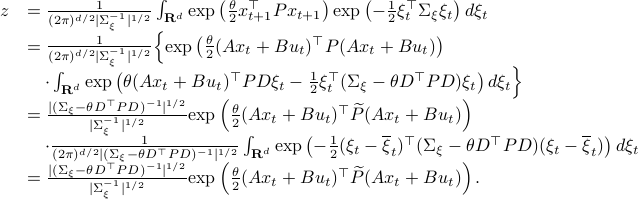
Here, the first step follows directly from 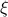 being a zero-mean Gaussian. In the second step we plug in
being a zero-mean Gaussian. In the second step we plug in 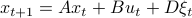 . Then, in the third step we introduce a variable
. Then, in the third step we introduce a variable 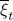 with the goal of making
with the goal of making 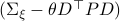 the covariance matrix of a Gaussian with mean . We can make this work for
the covariance matrix of a Gaussian with mean . We can make this work for
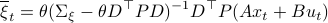
and additionally
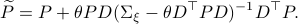
Using this approach we can integrate the latter part to  and end up with the final expression.
Note that in this case the random variable
and end up with the final expression.
Note that in this case the random variable 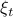 needs to be Gaussian, since the second to last expression in
needs to be Gaussian, since the second to last expression in  equals by being a Gaussian probability distribution integrated over its entire domain.
equals by being a Gaussian probability distribution integrated over its entire domain.
What is the point of doing this?
Let 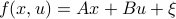 and assume that
and assume that 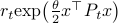 represents the cost-to-go from stage
represents the cost-to-go from stage 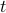 and state
and state 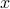 . Then consider
. Then consider
![r_{t-1}mathrm{exp}left(frac{theta}{2}x^{top}P_{t-1} xright) = inf_{u} left{mathrm{exp}left(frac{theta}{2}(x^{top}Qx+u^{top}Ru)right)mathbf{E}_{xi}left[r_tmathrm{exp}left( frac{theta}{2}f(x,u)^{top}P_{t}f(x,u)right);|;xright]right}.](eqs/8431854396343916570-130.png)
Note, since we work with a sum within the exponent, we must multiply within the right-hand-side of the Bellman equation.
From there it follows that
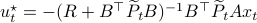 , for
, for
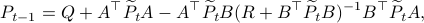
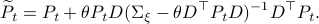
The key trick in simplifying your expressions is to apply the logarithm after minimizing over 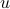 such that the fraction of determinants becomes a state-independent affine term in the cost.
Now, using a matrix inversion lemma and the push-through rule we can remove
such that the fraction of determinants becomes a state-independent affine term in the cost.
Now, using a matrix inversion lemma and the push-through rule we can remove 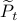 and construct a map
and construct a map 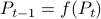 :
:
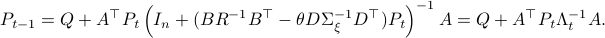
such that 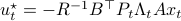 .
See below for the derivations, many (if not all) texts skip them, but if you have never applied the push-through rule they are not that obvious.
.
See below for the derivations, many (if not all) texts skip them, but if you have never applied the push-through rule they are not that obvious.
As was pointed out for the first time by Jacobson (Jac73), these equations are precisely the ones we see in (non-cooperative) Dynamic Game theory for isotropic 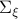 and appropriately scaled
and appropriately scaled 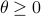 .
.
Especially with this observation in mind there are many texts which show that 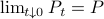 is well-defined and finite, which relates to finite cost and a stabilizing control law
is well-defined and finite, which relates to finite cost and a stabilizing control law 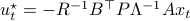 . To formalize this, one needs to assume that
. To formalize this, one needs to assume that 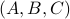 is a minimal realization for
is a minimal realization for 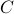 defined by
defined by 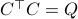 . Then you can appeal to texts like (BB95).
. Then you can appeal to texts like (BB95).
Numerical Experiment and Robustness Interpretation
To show what happens, we do a small 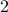 -dimensional example. Here we want to solve the Risk-Sensitive
-dimensional example. Here we want to solve the Risk-Sensitive 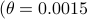 ) and the Risk-neutral () infinite-horizon average cost problem for
) and the Risk-neutral () infinite-horizon average cost problem for
![A = left[ begin{array}{ll} 2 & 1 0 & 2 end{array}right],quad B = left[ begin{array}{l} 0 1 end{array}right],quad Sigma_{xi}^{-1} = left[ begin{array}{ll} 10^{-1} & 200^{-1} 200^{-1} & 10 end{array}right],](eqs/5026564260006708683-130.png)
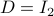 ,
, 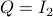 ,
, 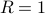 .
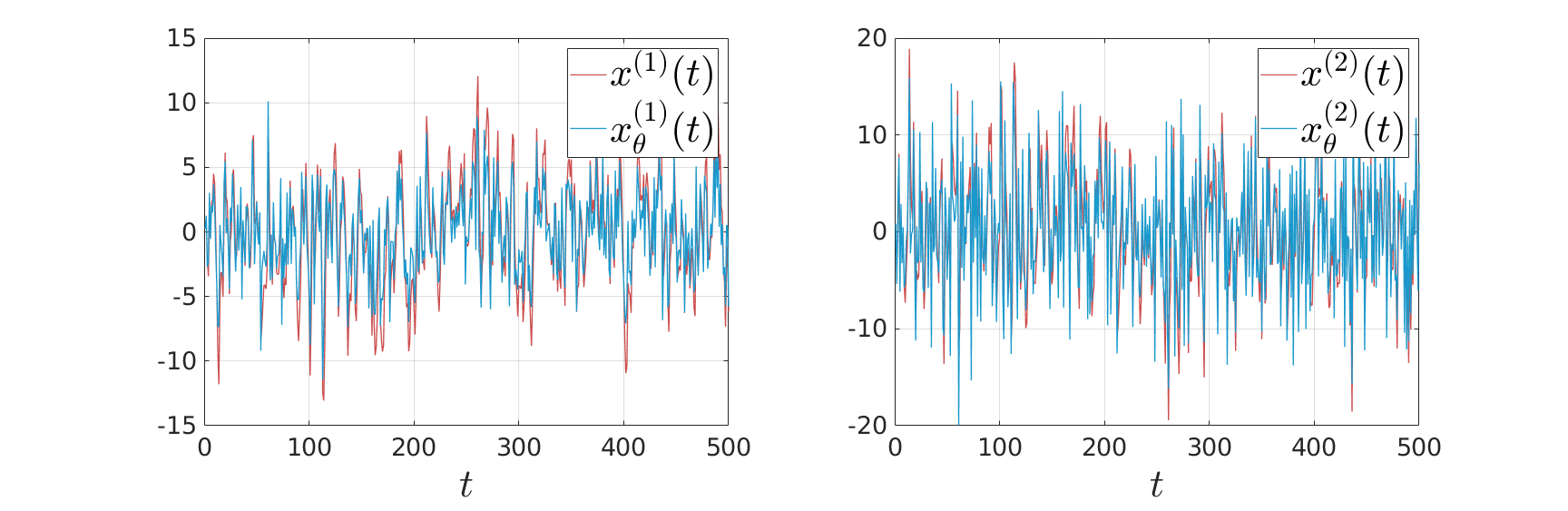
There is clearly a lot of noise, especially on the second signal, which also happens to be critical for controlling the first state. This makes it interesting.
We compute
.
There is clearly a lot of noise, especially on the second signal, which also happens to be critical for controlling the first state. This makes it interesting.
We compute 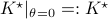 and
and 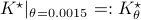 .
Given the noise statistics, it would be reasonable to not take the certainty equivalence control law
.
Given the noise statistics, it would be reasonable to not take the certainty equivalence control law 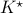 since you control the first state (which has little noise on its line) via the second state (which has a lot of noise on its line). Let
since you control the first state (which has little noise on its line) via the second state (which has a lot of noise on its line). Let 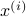 be the
be the 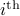 state under and
state under and 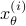 the state under
the state under 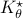 .
.
We see in the plot below (for some arbitrary initial condition) typical behaviour, does take the noise into account and indeed we see the induces a smaller variance.
 |
So, is more robust than in a particular way. It turns out that this can be neatly explained. To do so, we have to introduce the notion of Relative Entropy (Kullback-Leibler divergence). We will skip a few technical details (see the references for full details). Given a measure 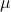 on
on 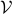 , then for any other measure
, then for any other measure 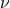 , being absolutely continuous with respect to (
, being absolutely continuous with respect to (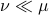 ), define the Relative Entropy as:
), define the Relative Entropy as:
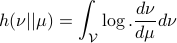
Now, for any measurable function 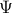 on , being bounded from below, it can be shown (see (DP96)) that
on , being bounded from below, it can be shown (see (DP96)) that
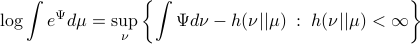
For the moment, think of as your standard finite-horizon LQR cost with product measure 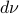 , then we see that an exponential utility results in the understanding that a control law which minimizes
, then we see that an exponential utility results in the understanding that a control law which minimizes 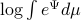 is robust against adversarial noise generated by distributions sufficiently close (measured by
is robust against adversarial noise generated by distributions sufficiently close (measured by 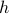 ) to the reference .
) to the reference .
Here we skipped over a lot of technical details, but the intuition is beautiful, just changing the utility to the exponential function gives a wealth of deep distributional results we just touched upon in this post.
Simplification steps in 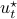
We only show to get the simpler representation for the input, the approach to obtain 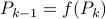 is very similar.
is very similar.
First, using the matrix inversion lemma:
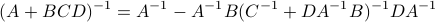
we rewrite into:
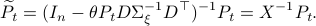
Note, we factored our 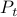 since we cannot assume that is invertible. Our next tool is called the push-through rule. Given
since we cannot assume that is invertible. Our next tool is called the push-through rule. Given 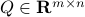 and
and 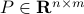 we have
we have
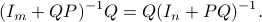
You can check that indeed 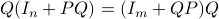 .
Now, to continue, plug this expression for into the input expression:
.
Now, to continue, plug this expression for into the input expression:
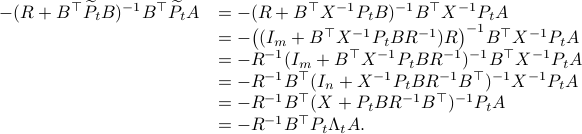
Indeed, we only used factorizations and the push-through rule to arrive here.
(Bert76) Dimitri P. Bertsekas : ‘‘Dynamic Programming and Stochastic Control’’, 1976 Academic Press.
(Jac73) D. Jacobson : ‘‘Optimal stochastic linear systems with exponential performance criteria and their relation to deterministic differential games’’, 1973 IEEE TAC.
(Wh90) Peter Whittle : ‘‘Risk-sensitive Optimal Control’’, 1990 Wiley.
(BB95) Tamer Basar and Pierre Bernhard : ‘‘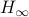 -Optimal Control and Related Minimax Design Problems A Dynamic Game Approach’’ 1995 Birkhauser.
-Optimal Control and Related Minimax Design Problems A Dynamic Game Approach’’ 1995 Birkhauser.
(DP96) Paolo Dai Pra, Lorenzo Meneghini and Wolfgang J. Runggaldier :‘‘Connections Between Stochastic Control and Dynamic Games’’ 1996 Math. Control Signals Systems.